最近抽零碎时间过了一个极客时间的专栏,感觉讲的还不错,本篇内容基本是原文复制粘贴了一些点过来,至于为啥没归纳总结,我说是因为时间原因,你也可以说是因为懒😂😂😂,总之这里做个记录,以备以后再看。有任何问题可以在我的博客留言,或者直接在CSDN留言。
ThreadLocal 使用要注意及时remove,既要防止内存溢出,也防止线程重用导致数据混乱
java8中lambda表达式的一些例子:
1
2
3
4
5
6
7
8
9
10
11
12//帮助方法,用来获得一个指定元素数量模拟数据的ConcurrentHashMap
private ConcurrentHashMap<String, Long> getData(int count) {
//longStream.rangeClosed获取一个[1-count]的LongStream
return LongStream.rangeClosed(1, count)
//将LongStream转化为Stream
.boxed()
.collect(Collectors.toConcurrentMap(i -> UUID.randomUUID().toString(),
//输入什么输出就是什么
Function.identity(),
(//键冲突时候保留现有的值,O1)
(o1, o2) -> o1, ConcurrentHashMap::new));
}使用concurrentHashMap并不代表一定线程安全,只能保证原子性操作是线程安全的.
在 Java 中,CopyOnWriteArrayList 虽然是一个线程安全的 ArrayList,但因为其实现方式是,每次修改数据时都会复制一份数据出来,所以有明显的适用场景,即读多写少或者说希望无锁读的场景。
computeIfAbsent和putIfAbsent区别是三点:
1、当Key存在的时候,如果Value获取比较昂贵的话,putIfAbsent就白白浪费时间在获取这个昂贵的Value上(这个点特别注意)
2、Key不存在的时候,putIfAbsent返回null,小心空指针,而computeIfAbsent返回计算后的值
3、当Key不存在的时候,putIfAbsent允许put null进去,而computeIfAbsent不能,之后进行containsKey查询是有区别的(当然了,此条针对HashMap,ConcurrentHashMap不允许put null value进去)思考与讨论
今天我们多次用到了 ThreadLocalRandom,你觉得是否可以把它的实例设置到静态变量中,在多线程情况下重用呢?ConcurrentHashMap 还提供了 putIfAbsent 方法,你能否通过查阅JDK 文档,说说 computeIfAbsent 和 putIfAbsent 方法的区别?
答案:
问题一:不可以。ThreadLocalRandom文档里写了Usages of this class should typically be of the form:ThreadLocalRandom.current().nextX(…)} (where X is Int, Long, etc)。
ThreadLocalRandom类中只封装了一些公用的方法,种子存放在各个线程中。
ThreadLocalRandom中存放一个单例的instance,调用current()方法返回这个instance,每个线程首次调用current()方法时,会在各个线程中初始化seed和probe。
nextX()方法会调用nextSeed(),在其中使用各个线程中的种子,计算下一个种子并保存(UNSAFE.getLong(t, SEED) + GAMMA)。
所以,如果使用静态变量,直接调用nextX()方法就跳过了各个线程初始化的步骤,只会在每次调用nextSeed()时来更新种子。问题二
1.参数不一样,putIfAbsent是值,computeIfAbsent是mappingFunction
2.返回值不一样,putIfAbsent是之前的值,computeIfAbsent是现在的值
3.putIfAbsent可以存入null,computeIfAbsent计算结果是null只会返回null,不会写入。
代码加锁:不要让“锁”事成为烦心事
加锁要考虑锁的粒度和场景问题
在方法上加 synchronized 关键字实现加锁确实简单,也因此我曾看到一些业务代码中几乎所有方法都加了 synchronized,但这种滥用 synchronized 的做法:
一是,没必要。通常情况下 60% 的业务代码是三层架构,数据经过无状态的 Controller、Service、Repository 流转到数据库,没必要使用 synchronized 来保护什么数据。
二是,可能会极大地降低性能。使用 Spring 框架时,默认情况下 Controller、Service、Repository 是单例的,加上 synchronized 会导致整个程序几乎就只能支持单线程,造成极大的性能问题。
线程池:业务代码最常用也最容易犯错的组件
不建议使用 Executors 提供的两种快捷的线程池
原因如下:我们需要根据自己的场景、并发情况来评估线程池的几个核心参数,包括核心线程数、最大线程数、线程回收策略、工作队列的类型,以及拒绝策略,确保线程池的工作行为符合需求,一般都需要设置有界的工作队列和可控的线程数。任何时候,都应该为自定义线程池指定有意义的名称,以方便排查问题。当出现线程数量暴增、线程死锁、线程占用大量 CPU、线程执行出现异常等问题时,我们往往会抓取线程栈。此时,有意义的线程名称,就可以方便我们定位问题。
除了建议手动声明线程池以外,我还建议用一些监控手段来观察线程池的状态。线程池这个组件往往会表现得任劳任怨、默默无闻,除非是出现了拒绝策略,否则压力再大都不会抛出一个异常。如果我们能提前观察到线程池队列的积压,或者线程数量的快速膨胀,往往可以提早发现并解决问题
需要仔细斟酌线程池的混用策略,线程池的意义在于复用
那这是不是意味着程序应该始终使用一个线程池呢?当然不是。通过第一小节的学习我们知道,要根据任务的“轻重缓急”来指定线程池的核心参数,包括线程数、回收策略和任务队列:对于执行比较慢、数量不大的 IO 任务,或许要考虑更多的线程数,而不需要太大的队列。而对于吞吐量较大的计算型任务,线程数量不宜过多,可以是 CPU 核数或核数 *2(理由是,线程一定调度到某个 CPU 进行执行,如果任务本身是 CPU 绑定的任务,那么过多的线程只会增加线程切换的开销,并不能提升吞吐量),但可能需要较长的队列来做缓冲。
就线程池混用问题,我想再和你补充一个坑:Java 8 的 parallel stream 功能,可以让我们很方便地并行处理集合中的元素,其背后是共享同一个 ForkJoinPool,默认并行度是 CPU 核数 -1。对于 CPU 绑定的任务来说,使用这样的配置比较合适,但如果集合操作涉及同步 IO 操作的话(比如数据库操作、外部服务调用等),建议自定义一个 ForkJoinPool(或普通线程池)。你可以参考第一讲的相关 Demo
连接池:别让连接池帮了倒忙
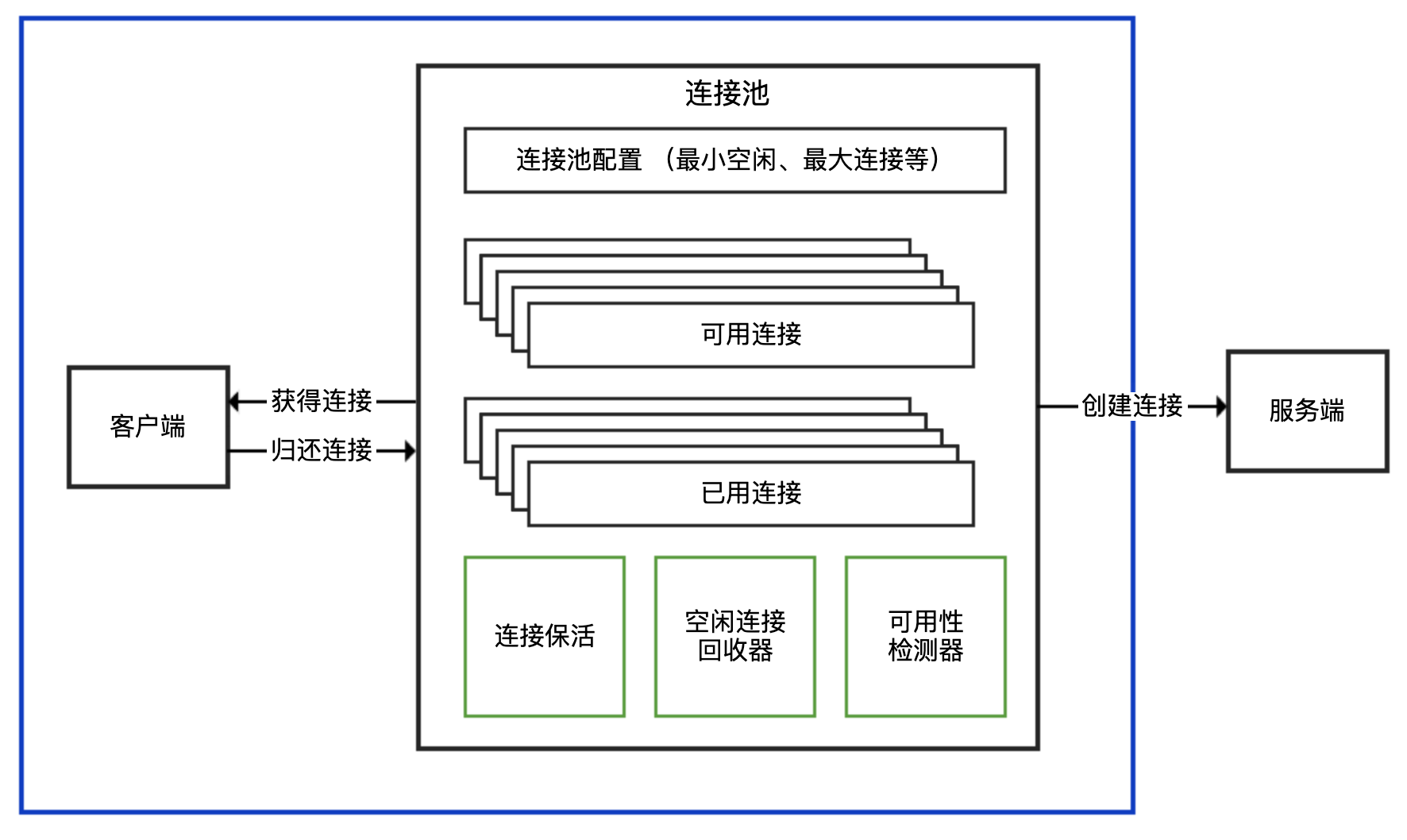
面对各种三方客户端的时候,只有先识别出其属于哪一种,才能理清楚使用方式。
连接池和连接分离的 API:有一个 XXXPool 类负责连接池实现,先从其获得连接 XXXConnection,然后用获得的连接进行服务端请求,完成后使用者需要归还连接。通常,XXXPool 是线程安全的,可以并发获取和归还连接,而 XXXConnection 是非线程安全的。对应到连接池的结构示意图中,XXXPool 就是右边连接池那个框,左边的客户端是我们自己的代码。
内部带有连接池的 API:对外提供一个 XXXClient 类,通过这个类可以直接进行服务端请求;这个类内部维护了连接池,SDK 使用者无需考虑连接的获取和归还问题。一般而言,XXXClient 是线程安全的。对应到连接池的结构示意图中,整个 API 就是蓝色框包裹的部分。
非连接池的 API:一般命名为 XXXConnection,以区分其是基于连接池还是单连接的,而不建议命名为 XXXClient 或直接是 XXX。直接连接方式的 API 基于单一连接,每次使用都需要创建和断开连接,性能一般,且通常不是线程安全的。对应到连接池的结构示意图中,这种形式相当于没有右边连接池那个框,客户端直接连接服务端创建连接。
明确了 SDK 连接池的实现方式后,我们就大概知道了使用 SDK 的最佳实践:
如果是分离方式,那么连接池本身一般是线程安全的,可以复用。每次使用需要从连接池获取连接,使用后归还,归还的工作由使用者负责。
如果是内置连接池,SDK 会负责连接的获取和归还,使用的时候直接复用客户端。
如果 SDK 没有实现连接池(大多数中间件、数据库的客户端 SDK 都会支持连接池),那通常不是线程安全的,而且短连接的方式性能不会很高,使用的时候需要考虑是否自己封装一个连接池。
Jedis本身线程不安全,想要线程安全使用JedisPool获取Jedis实例
优雅的关闭线程池
1 |
|
Jedis 的 API 实现是我们说的三种类型中的第一种,也就是连接池和连接分离的 API,JedisPool 是线程安全的连接池,Jedis 是非线程安全的单一连接。
连接池的配置不是一成不变的
为方便根据容量规划设置连接处的属性,连接池提供了许多参数,包括最小(闲置)连接、最大连接、闲置连接生存时间、连接生存时间等。其中,最重要的参数是最大连接数,它决定了连接池能使用的连接数量上限,达到上限后,新来的请求需要等待其他请求释放连接。
但,最大连接数不是设置得越大越好。如果设置得太大,不仅仅是客户端需要耗费过多的资源维护连接,更重要的是由于服务端对应的是多个客户端,每一个客户端都保持大量的连接,会给服务端带来更大的压力。这个压力又不仅仅是内存压力,可以想一下如果服务端的网络模型是一个 TCP 连接一个线程,那么几千个连接意味着几千个线程,如此多的线程会造成大量的线程切换开销。
当然,连接池最大连接数设置得太小,很可能会因为获取连接的等待时间太长,导致吞吐量低下,甚至超时无法获取连接。
HTTP调用:你考虑到超时、重试、并发了吗?
几乎所有的网络框架都会提供这么两个超时参数:
连接超时参数 ConnectTimeout,让用户配置建连阶段的最长等待时间;
读取超时参数 ReadTimeout,用来控制从 Socket 上读取数据的最长等待时间。
这两个参数看似是网络层偏底层的配置参数,不足以引起开发同学的重视。但,正确理解和配置这两个参数,对业务应用特别重要,毕竟超时不是单方面的事情,需要客户端和服务端对超时有一致的估计,协同配合方能平衡吞吐量和错误率。
因为 TCP 是先建立连接后传输数据,对于网络情况不是特别糟糕的服务调用,通常可以认为出现连接超时是网络问题或服务不在线,而出现读取超时是服务处理超时。确切地说,读取超时指的是,向 Socket 写入数据后,我们等到 Socket 返回数据的超时时间,其中包含的时间或者说绝大部分的时间,是服务端处理业务逻辑的时间。
默认情况下 Feign 的读取超时是 1 秒,如此短的读取超时算是坑点一。
如果要配置 Feign 的读取超时,就必须同时配置连接超时,才能生效。
除了可以配置 Feign,也可以配置 Ribbon 组件的参数来修改两个超时时间。这里的坑点三是,参数首字母要大写,和 Feign 的配置不同。ribbon.ReadTimeout=4000 ribbon.ConnectTimeout=4000
同时配置 Feign 和 Ribbon 的参数,最终谁会生效?答案是feign
翻看 Ribbon 的源码可以发现,MaxAutoRetriesNextServer 参数默认为 1,也就是 Get 请求在某个服务端节点出现问题(比如读取超时)时,Ribbon 会自动重试一次:
Spring事务生效
如果你捕获了异常,还想让事务生效,如下处理:
1 |
|
数据库索引
创建辅助索引的代价
创建二级索引的代价,主要表现在维护代价、空间代价和回表代价三个方面
首先是维护代价。创建 N 个二级索引,就需要再创建 N 棵 B+ 树,新增数据时不仅要修改聚簇索引,还需要修改这 N 个二级索引。
其次是空间代价。虽然二级索引不保存原始数据,但要保存索引列的数据,所以会占用更多的空间。比如,person 表创建了两个索引后,使用下面的 SQL 查看数据和索引占用的磁盘:
1 | SELECT DATA_LENGTH, INDEX_LENGTH FROM information_schema.TABLES WHERE TABLE_NAME='person' |
最后是回表的代价。二级索引不保存原始数据,通过索引找到主键后需要再查询聚簇索引,才能得到我们要的数据
有时会因为统计信息的不准确或成本估算的问题,实际开销会和 MySQL 统计出来的差距较大,导致 MySQL 选择错误的索引或是直接选择走全表扫描,这个时候就需要人工干预,使用强制索引了。比如,像这样强制走 name_score 索引
1 | EXPLAIN SELECT * FROM person FORCE INDEX(name_score) WHERE NAME >'name84059' AND create_time>'2020-01-24 05:00:00' |
在 MySQL 5.6 及之后的版本中,我们可以使用 optimizer trace 功能查看优化器生成执行计划的整个过程。有了这个功能,我们不仅可以了解优化器的选择过程,更可以了解每一个执行环节的成本,然后依靠这些信息进一步优化查询
如下代码所示,打开 optimizer_trace 后,再执行 SQL 就可以查询 information_schema.OPTIMIZER_TRACE 表查看执行计划了,最后可以关闭 optimizer_trace 功能:
1 | SET optimizer_trace="enabled=on"; |
思考与讨论
索引除了可以用于加速搜索外,还可以在排序时发挥作用,你能通过 EXPLAIN 来证明吗?你知道,在什么情况下针对排序索引会失效吗?
第二个问题:
SQL中带order by且执行计划中Extra 这个字段中有”Using index”或者”Using index condition”表示用到索引,并且不用专门排序,因为索引本身就是有序的;
如果Extra有“Using filesort”表示的就是需要排序;排序时:MySQL 会给每个线程分配一块内存用于排序,称为 sort_buffer。sort_buffer_size(sort_buffer)的大小。如果要排序的数据量小于 sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
上述排序中,只对原表的数据读了一遍,剩下的操作都是在 sort_buffer 和临时文件中执行的。但这个算法有一个问题,就是如果查询要返回的字段很多的话,那么 sort_buffer 里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。所以如果单行很大,这个方法效率不够好。max_length_for_sort_data,是 MySQL 中专门控制用于排序的行数据的长度的一个参数。它的意思是,如果单行的长度超过这个值,MySQL 就认为单行太大,要换一个算法。称为 rowid 排序;
rowid排序简单的描述就是先取出ID和排序字段进行排序,排序结束后,用ID回表去查询select中出现的其他字段,多了一次回表操作,
对于 InnoDB 表来说,rowid 排序会要求回表多造成磁盘读,因此不会被优先选择。
判等问题:程序里如何确定你就是你
比较值的内容,除了基本类型只能使用 == 外,其他类型都需要使用 equals。
对于自定义的类型,如果要实现 Comparable,请记得 equals、hashCode、compareTo 三者逻辑一致。
小心 Lombok 生成代码的“坑”
Lombok 的 @Data 注解会帮我们实现 equals 和 hashcode 方法,但是有继承关系时,Lombok 自动生成的方法可能就不是我们期望的了。我们先来研究一下其实现:定义一个 Person 类型,包含姓名和身份证两个字段:
1 |
|
对于身份证相同、姓名不同的两个 Person 对象:
1 | Person person1 = new Person("zhuye","001"); |
使用 equals 判等会得到 false。如果你希望只要身份证一致就认为是同一个人的话,可以使用 @EqualsAndHashCode.Exclude 注解来修饰 name 字段,从 equals 和 hashCode 的实现中排除 name 字段:
如果类型之间有继承,Lombok 会怎么处理子类的 equals 和 hashCode 呢?
@EqualsAndHashCode 默认实现没有使用父类属性。
为解决这个问题,我们可以手动设置 callSuper 开关为 true,来覆盖这种默认行为:
@EqualsAndHashCode(callSuper = true)
数值计算:注意精度、舍入和溢出问题
这里给出浮点数运算避坑第一原则:使用 BigDecimal 表示和计算浮点数,且
务必使用字符串的构造方法来初始化 BigDecimal:
BigDecimal 有 scale 和 precision 的概念,scale 表示小数点右边的位数,而 precision 表示精度,也就是有效数字的长度。
对于 BigDecimal 乘法操作,返回值的 scale 是两个数的 scale 相加
浮点数避坑第二原则:浮点数的字符串格式化也要通过 BigDecimal 进行。
比如下面这段代码,使用 BigDecimal 来格式化数字 3.35,分别使用向下舍入和四舍五入方式取 1 位小数进行格式化:
1 | BigDecimal num1 = new BigDecimal("3.35"); |
这次得到的结果是 3.3 和 3.4,符合预期
如果我们希望只比较 BigDecimal 的 value,可以使用 compareTo 方法 , equals 比较的是 BigDecimal 的 value 和 scale
比如如下返回false:
1 | System.out.println(new BigDecimal("1.0").equals(new BigDecimal("1"))) |
BigDecimal 的 equals 和 hashCode 方法会同时考虑 value 和 scale,如果结合 HashSet 或 HashMap 使用的话就可能会出现麻烦。比如,我们把值为 1.0 的 BigDecimal 加入 HashSet,然后判断其是否存在值为 1 的 BigDecimal,得到的结果是 false:
1 | Set<BigDecimal> hashSet1 = new HashSet<>(); |
解决这个问题的办法有两个:第一个方法是,使用 TreeSet 替换 HashSet。TreeSet 不使用 hashCode 方法,也不使用 equals 比较元素,而是使用 compareTo 方法,所以不会有问题。
1 | Set<BigDecimal> treeSet = new TreeSet<>(); |
第二个方法是,把 BigDecimal 存入 HashSet 或 HashMap 前,先使用 stripTrailingZeros 方法去掉尾部的零,比较的时候也去掉尾部的 0,确保 value 相同的 BigDecimal,scale 也是一致的:
1 | Set<BigDecimal> hashSet2 = new HashSet<>(); |
小心数值溢出问题
数值计算还有一个要小心的点是溢出,不管是 int 还是 long,所有的基本数值类型都有超出表达范围的可能性。比如,对 Long 的最大值进行 +1 操作:
1 | long l = Long.MAX_VALUE; |
输出结果是一个负数,因为 Long 的最大值 +1 变为了 Long 的最小值
1 | -9223372036854775808 |
显然这是发生了溢出,而且是默默的溢出,并没有任何异常。这类问题非常容易被忽略,改进方式有下面 2 种。方法一是,考虑使用 Math 类的 addExact、subtractExact 等 xxExact 方法进行数值运算,这些方法可以在数值溢出时主动抛出异常。我们来测试一下,使用 Math.addExact 对 Long 最大值做 +1 操作:
1 | try { |
执行后,可以得到 ArithmeticException,这是一个 RuntimeException:
方法二是,使用大数类 BigInteger。BigDecimal 是处理浮点数的专家,而 BigInteger 则是对大数进行科学计算的专家。
如下代码,使用 BigInteger 对 Long 最大值进行 +1 操作;如果希望把计算结果转换一个 Long 变量的话,可以使用 BigInteger 的 longValueExact 方法,在转换出现溢出时,同样会抛出 ArithmeticException:
1 | BigInteger i = new BigInteger(String.valueOf(Long.MAX_VALUE)); |
输出结果如下:
1 | 9223372036854775808 |
可以看到,通过 BigInteger 对 Long 的最大值加 1 一点问题都没有,当尝试把结果转换为 Long 类型时,则会提示 BigInteger out of long range。
BigDecimal提供了 8 种舍入模式,你能通过一些例子说说它们的区别吗?
1、 ROUND_UP
舍入远离零的舍入模式。
在丢弃非零部分之前始终增加数字(始终对非零舍弃部分前面的数字加1)。
注意,此舍入模式始终不会减少计算值的大小。
2、ROUND_DOWN
接近零的舍入模式。
在丢弃某部分之前始终不增加数字(从不对舍弃部分前面的数字加1,即截短)。
注意,此舍入模式始终不会增加计算值的大小。
3、ROUND_CEILING
接近正无穷大的舍入模式。
如果 BigDecimal 为正,则舍入行为与 ROUND_UP 相同;
如果为负,则舍入行为与 ROUND_DOWN 相同。
注意,此舍入模式始终不会减少计算值。
4、ROUND_FLOOR
接近负无穷大的舍入模式。
如果 BigDecimal 为正,则舍入行为与 ROUND_DOWN 相同;
如果为负,则舍入行为与 ROUND_UP 相同。
注意,此舍入模式始终不会增加计算值。
5、ROUND_HALF_UP
向“最接近的”数字舍入,如果与两个相邻数字的距离相等,则为向上舍入的舍入模式。
如果舍弃部分 >= 0.5,则舍入行为与 ROUND_UP 相同;否则舍入行为与 ROUND_DOWN 相同。
注意,这是我们大多数人在小学时就学过的舍入模式(四舍五入)。
6、ROUND_HALF_DOWN
向“最接近的”数字舍入,如果与两个相邻数字的距离相等,则为上舍入的舍入模式。
如果舍弃部分 > 0.5,则舍入行为与 ROUND_UP 相同;否则舍入行为与 ROUND_DOWN 相同(五舍六入)。
7、ROUND_HALF_EVEN
向“最接近的”数字舍入,如果与两个相邻数字的距离相等,则向相邻的偶数舍入。
如果舍弃部分左边的数字为奇数,则舍入行为与 ROUND_HALF_UP 相同;
如果为偶数,则舍入行为与 ROUND_HALF_DOWN 相同。
注意,在重复进行一系列计算时,此舍入模式可以将累加错误减到最小。
此舍入模式也称为“银行家舍入法”,主要在美国使用。四舍六入,五分两种情况。
如果前一位为奇数,则入位,否则舍去。
以下例子为保留小数点1位,那么这种舍入方式下的结果。
1.15>1.2 1.25>1.2
8、ROUND_UNNECESSARY
断言请求的操作具有精确的结果,因此不需要舍入。
如果对获得精确结果的操作指定此舍入模式,则抛出ArithmeticException。
集合类:坑满地的List列表操作
使用 Arrays.asList 把数据转换为 List 的三个坑
在如下代码中,我们初始化三个数字的 int[]数组,然后使用 Arrays.asList 把数组转换为 List:
1 | int[] arr = {1, 2, 3}; |
但,这样初始化的 List 并不是我们期望的包含 3 个数字的 List。通过日志可以发现,这个 List 包含的其实是一个 int 数组,整个 List 的元素个数是 1,元素类型是整数数组。
其原因是,只能是把 int 装箱为 Integer,不可能把 int 数组装箱为 Integer 数组。我们知道,Arrays.asList 方法传入的是一个泛型 T 类型可变参数,最终 int 数组整体作为了一个对象成为了泛型类型 T:
1 | public static <T> List<T> asList(T... a) { |
直接遍历这样的 List 必然会出现 Bug,修复方式有两种,如果使用 Java8 以上版本可以使用 Arrays.stream 方法来转换,否则可以把 int 数组声明为包装类型 Integer 数组:
1 | int[] arr1 = {1, 2, 3}; |
第二个坑,Arrays.asList 返回的 List 不支持增删操作。Arrays.asList 返回的 List 并不是我们期望的 java.util.ArrayList,而是 Arrays 的内部类 ArrayList
第三个坑,对原始数组的修改会影响到我们获得的那个 List。
看一下 ArrayList 的实现,可以发现 ArrayList 其实是直接使用了原始的数组。所以,我们要特别小心,把通过 Arrays.asList 获得的 List 交给其他方法处理,很容易因为共享了数组,相互修改产生 Bug。
修复方式比较简单,重新 new 一个 ArrayList 初始化 Arrays.asList 返回的 List 即可:
1 | String[] arr = {"1", "2", "3"}; |
使用 List.subList 进行切片操作居然会导致 OOM?
业务开发时常常要对 List 做切片处理,即取出其中部分元素构成一个新的 List,我们通常会想到使用 List.subList 方法。但,和 Arrays.asList 的问题类似,List.subList 返回的子 List 不是一个普通的 ArrayList。这个子 List 可以认为是原始 List 的视图,会和原始 List 相互影响。如果不注意,很可能会因此产生 OOM 问题
SubList 相当于原始 List 的视图,那么避免相互影响的修复方式有两种:一种是,不直接使用 subList 方法返回的 SubList,而是重新使用 new ArrayList,在构造方法传入 SubList,来构建一个独立的 ArrayList;另一种是,对于 Java 8 使用 Stream 的 skip 和 limit API 来跳过流中的元素,以及限制流中元素的个数,同样可以达到 SubList 切片的目的。
1 | //方式一: |
如果要对大 ArrayList 进行去重操作,也不建议使用 contains 方法,而是可以考虑使用 HashSet 进行去重
空值处理:分不清楚的null和恼人的空指针
NullPointerException 是 Java 代码中最常见的异常,最可能出现的场景归为以下 5 种:
- 参数值是 Integer 等包装类型,使用时因为自动拆箱出现了空指针异常;
- 字符串比较出现空指针异常;
- 诸如 ConcurrentHashMap 这样的容器不支持 Key 和 Value 为 null,强行 put null 的 Key 或 Value 会出现空指针异常;
- A 对象包含了 B,在通过 A 对象的字段获得 B 之后,没有对字段判空就级联调用 B 的方法出现空指针异常;
- 方法或远程服务返回的 List 不是空而是 null,没有进行判空就直接调用 List 的方法出现空指针异常。
纯粹的空指针判空这种修复方式。如果要先判空后处理,大多数人会想到使用 if-else 代码块。但,这种方式既增加代码量又会降低易读性,我们可以尝试利用 Java 8 的 Optional 类来消除这样的 if-else 逻辑,使用一行代码进行判空和处理。修复思路如下:
对于 Integer 的判空,可以使用 Optional.ofNullable 来构造一个 Optional,然后使用 orElse(0) 把 null 替换为默认值再进行 +1 操作。
对于 String 和字面量的比较,可以把字面量放在前面,比如”OK”.equals(s),这样即使 s 是 null 也不会出现空指针异常;而对于两个可能为 null 的字符串变量的 equals 比较,可以使用 Objects.equals,它会做判空处理。
对于 ConcurrentHashMap,既然其 Key 和 Value 都不支持 null,修复方式就是不要把 null 存进去。HashMap 的 Key 和 Value 可以存入 null,而 ConcurrentHashMap 看似是 HashMap 的线程安全版本,却不支持 null 值的 Key 和 Value,这是容易产生误区的一个地方。
对于类似 fooService.getBarService().bar().equals(“OK”) 的级联调用,需要判空的地方有很多,包括 fooService、getBarService() 方法的返回值,以及 bar 方法返回的字符串。如果使用 if-else 来判空的话可能需要好几行代码,但使用 Optional 的话一行代码就够了。
对于 rightMethod 返回的 List,由于不能确认其是否为 null,所以在调用 size 方法获得列表大小之前,同样可以使用 Optional.ofNullable 包装一下返回值,然后通过.orElse(Collections.emptyList()) 实现在 List 为 null 的时候获得一个空的 List,最后再调用 size 方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17private List<String> rightMethod(FooService fooService, Integer i, String s, String t) {
log.info("result {} {} {} {}", Optional.ofNullable(i).orElse(0) + 1, "OK".equals(s), Objects.equals(s, t), new HashMap<String, String>().put(null, null));
Optional.ofNullable(fooService)
.map(FooService::getBarService)
.filter(barService -> "OK".equals(barService.bar()))
.ifPresent(result -> log.info("OK"));
return new ArrayList<>();
}
("right")
public int right(@RequestParam(value = "test", defaultValue = "1111") String test) {
return Optional.ofNullable(rightMethod(test.charAt(0) == '1' ? null : new FooService(),
test.charAt(1) == '1' ? null : 1,
test.charAt(2) == '1' ? null : "OK",
test.charAt(3) == '1' ? null : "OK"))
.orElse(Collections.emptyList()).size();
}使用判空方式或 Optional 方式来避免出现空指针异常,不一定是解决问题的最好方式,空指针没出现可能隐藏了更深的 Bug 因此,解决空指针异常,还是要真正 case by case 地定位分析案例,然后再去做判空处理,而处理时也并不只是判断非空然后进行正常业务流程这么简单,同样需要考虑为空的时候是应该出异常、设默认值还是记录日志等。
小心 MySQL 中有关 NULL 的三个坑
MySQL 中 sum 函数没统计到任何记录时,会返回 null 而不是 0,可以使用 IFNULL 函数把 null 转换为 0;
MySQL 中 count 字段不统计 null 值,COUNT(*) 才是统计所有记录数量的正确方式。
MySQL 中使用诸如 =、<、> 这样的算数比较操作符比较 NULL 的结果总是 NULL,这种比较就显得没有任何意义,需要使用 IS NULL、IS NOT NULL 或 ISNULL() 函数来比较。
捕获和处理异常容易犯的错
“统一异常处理”方式正是我要说的第一个错:不在业务代码层面考虑异常处理,仅在框架层面粗犷捕获和处理异常。
不建议在框架层面进行异常的自动、统一处理,尤其不要随意捕获异常。但,框架可以做兜底工作。如果异常上升到最上层逻辑还是无法处理的话,可以以统一的方式进行异常转换,比如通过 @RestControllerAdvice + @ExceptionHandler,来捕获这些“未处理”异常:
- 对于自定义的业务异常,以 Warn 级别的日志记录异常以及当前 URL、执行方法等信息后,提取异常中的错误码和消息等信息,转换为合适的 API 包装体返回给 API 调用方;
- 对于无法处理的系统异常,以 Error 级别的日志记录异常和上下文信息(比如 URL、参数、用户 ID)后,转换为普适的“服务器忙,请稍后再试”异常信息,同样以 API 包装体返回给调用方。
比如下面的代码:
1 |
|
第二个错,捕获了异常后直接生吞。在任何时候,我们捕获了异常都不应该生吞,也就是直接丢弃异常不记录、不抛出。
这样的处理方式还不如不捕获异常,因为被生吞掉的异常一旦导致 Bug,就很难在程序中找到蛛丝马迹,使得 Bug 排查工作难上加难。
第三个错,丢弃异常的原始信息。我们来看两个不太合适的异常处理方式,虽然没有完全生吞异常,但也丢失了宝贵的异常信息。
像这样调用 readFile 方法,捕获异常后,完全不记录原始异常,直接抛出一个转换后异常,导致出了问题不知道 IOException 具体是哪里引起的:
1 | ("wrong1") |
或者是这样,只记录了异常消息,却丢失了异常的类型、栈等重要信息:
1 | catch (IOException e) { |
留下的日志是这样的,看完一脸茫然,只知道文件读取错误的文件名,至于为什么读取错误、是不存在还是没权限,完全不知道。
1 | [12:57:19.746] [http-nio-45678-exec-1] [ERROR] [.g.t.c.e.d.HandleExceptionController:35 ] - 文件读取错误, a_file |
这两种处理方式都不太合理,可以改为如下方式:
1 | catch (IOException e) { |
或者,把原始异常作为转换后新异常的 cause,原始异常信息同样不会丢:
1 | catch (IOException e) { |
第四个错,抛出异常时不指定任何消息。我见过一些代码中的偷懒做法,直接抛出没有 message 的异常:
1 | throw new RuntimeException(); |
如果你捕获了异常打算处理的话,除了通过日志正确记录异常原始信息外,通常还有三种处理模式
- 转换,即转换新的异常抛出。对于新抛出的异常,最好具有特定的分类和明确的异常消息,而不是随便抛一个无关或没有任何信息的异常,并最好通过 cause 关联老异常。
- 重试,即重试之前的操作。比如远程调用服务端过载超时的情况,盲目重试会让问题更严重,需要考虑当前情况是否适合重试。
- 恢复,即尝试进行降级处理,或使用默认值来替代原始数据
小心 finally 中的异常
有些时候,我们希望不管是否遇到异常,逻辑完成后都要释放资源,这时可以使用 finally 代码块而跳过使用 catch 代码块。但要千万小心 finally 代码块中的异常,因为资源释放处理等收尾操作同样也可能出现异常。比如下面这段代码,我们在 finally 中抛出一个异常:
1 | ("wrong") |
最后在日志中只能看到 finally 中的异常,虽然 try 中的逻辑出现了异常,但却被 finally 中的异常覆盖了。这是非常危险的,特别是 finally 中出现的异常是偶发的,就会在部分时候覆盖 try 中的异常,让问题更不明显:
至于异常为什么被覆盖,原因也很简单,因为一个方法无法出现两个异常。修复方式是,finally 代码块自己负责异常捕获和处理:
1 | ("right") |
或者可以把 try 中的异常作为主异常抛出,使用 addSuppressed 方法把 finally 中的异常附加到主异常上
1 | ("right2") |
运行方法可以得到如下异常信息,其中同时包含了主异常和被屏蔽的异常:
1 | java.lang.RuntimeException: try |
其实这正是 try-with-resources 语句的做法,对于实现了 AutoCloseable 接口的资源,建议使用 try-with-resources 来释放资源,否则也可能会产生刚才提到的,释放资源时出现的异常覆盖主异常的问题。
千万别把异常定义为静态变量
提交线程池的任务出了异常会怎么样? 提交线程池的任务出了异常会怎么样?
修复方式有 2 步:
以 execute 方法提交到线程池的异步任务,最好在任务内部做好异常处理;
设置自定义的异常处理程序作为保底,比如在声明线程池时自定义线程池的未捕获异常处理程序:
通过线程池 ExecutorService 的 execute 方法提交任务到线程池处理,如果出现异常会导致线程退出,控制台输出中可以看到异常信息。那么,把 execute 方法改为 submit,线程还会退出吗,异常还能被处理程序捕获到吗?
线程没退出 ,异常也没记录被生吞了
查看 FutureTask 源码可以发现,在执行任务出现异常之后,异常存到了一个 outcome 字段中,只有在调用 get 方法获取 FutureTask 结果的时候,才会以 ExecutionException 的形式重新抛出异常:
思考与讨论:
关于在 finally 代码块中抛出异常的坑,如果在 finally 代码块中返回值,你觉得程序会以 try 或 catch 中返回值为准,还是以 finally 中的返回值为准呢?
对于手动抛出的异常,不建议直接使用 Exception 或 RuntimeException,通常建议复用 JDK 中的一些标准异常,比如IllegalArgumentException、IllegalStateException、UnsupportedOperationException,你能说说它们的适用场景,并列出更多常用异常吗?
第一个问题:
肯定是以finally语句块为准。
原因:首先需要明白的是在编译生成的字节码中,每个方法都附带一个异常表。异常表中的每一个条目代表一个异常处理器,并且由 from 指针、to 指针、target 指针以及所捕获的异常类型构成。这些指针的值是字节码索引(bytecode index,bci),用以定位字节码。其中,from 指针和 to 指针标示了该异常处理器所监控的范围,例如 try 代码块所覆盖的范围。target 指针则指向异常处理器的起始位置,例如 catch 代码块的起始位置;
当程序触发异常时,Java 虚拟机会从上至下遍历异常表中的所有条目。当触发异常的字节码的索引值在某个异常表条目的监控范围内,Java 虚拟机会判断所抛出的异常和该条目想要捕获的异常是否匹配。如果匹配,Java 虚拟机会将控制流转移至该条目 target 指针指向的字节码。如果遍历完所有异常表条目,Java 虚拟机仍未匹配到异常处理器,那么它会弹出当前方法对应的 Java 栈帧,并且在调用者(caller)中重复上述操作。在最坏情况下,Java 虚拟机需要遍历当前线程 Java 栈上所有方法的异常表。所以异常操作是一个非常耗费性能的操作;
finally 代码块的原理是复制 finally 代码块的内容,分别放在 try-catch 代码块所有正常执行路径以及异常执行路径的出口中。所以不管是是正常还是异常执行,finally都是最后执行的,所以肯定是finally语句块中为准。第二个问题:
IllegalArgumentException:不合法的参数异常,比如说限制不能为空或者有指定的发小范围,调用方没有按照规定传递参数,就可以抛出这个异常;
IllegalStateException:如果有状态流转的概念在里面(比如状态机),状态只能从A->B->C,若状态直接从A->C,就可以抛出该异常;
UnsupportedOperationException:不支持该操作异常,比如非抽象父类中有个方法,子类必须实现,父类中的方法就可以抛出次异常。老师在集合坑中提到的Arrays.asList 返回的 List 并不是我们期望的 java.util.ArrayList,而是 Arrays 的内部类 ArrayList。ArrayList 内部类继承自 AbstractList 类,并没有覆写父类的 add 方法,而父类中 add 方法的实现,就是抛出 UnsupportedOperationException。
日志:日志记录真没你想象的那么简单
Logback、Log4j、Log4j2、commons-logging、JDK 自带的 java.util.logging 等,都是 Java 体系的日志框架,确实非常多。而不同的类库,还可能选择使用不同的日志框架。这样一来,日志的统一管理就变得非常困难。为了解决这个问题,就有了 SLF4J(Simple Logging Facade For Java),如下图所示:
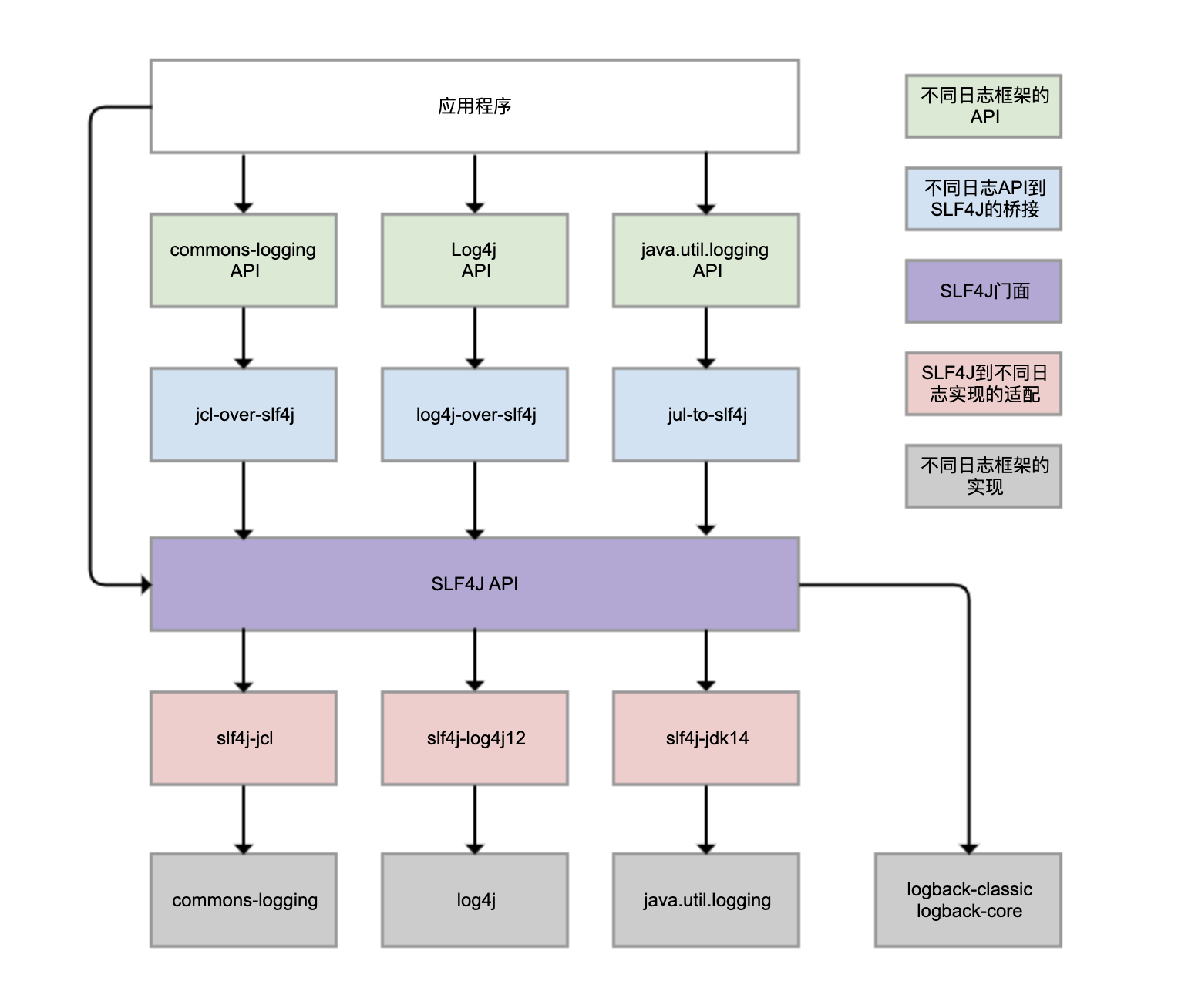
SLF4J 实现了三种功能:
一是提供了统一的日志门面 API,即图中紫色部分,实现了中立的日志记录 API。
二是桥接功能,即图中蓝色部分,用来把各种日志框架的 API(图中绿色部分)桥接到 SLF4J API。这样一来,即便你的程序中使用了各种日志 API 记录日志,最终都可以桥接到 SLF4J 门面 API。
三是适配功能,即图中红色部分,可以实现 SLF4J API 和实际日志框架(图中灰色部分)的绑定。SLF4J 只是日志标准,我们还是需要一个实际的日志框架。日志框架本身没有实现 SLF4J API,所以需要有一个前置转换。Logback 就是按照 SLF4J API 标准实现的,因此不需要绑定模块做转换。
需要理清楚的是,虽然我们可以使用 log4j-over-slf4j 来实现 Log4j 桥接到 SLF4J,也可以使用 slf4j-log4j12 实现 SLF4J 适配到 Log4j,也把它们画到了一列,但是它不能同时使用它们,否则就会产生死循环。jcl 和 jul 也是同样的道理。
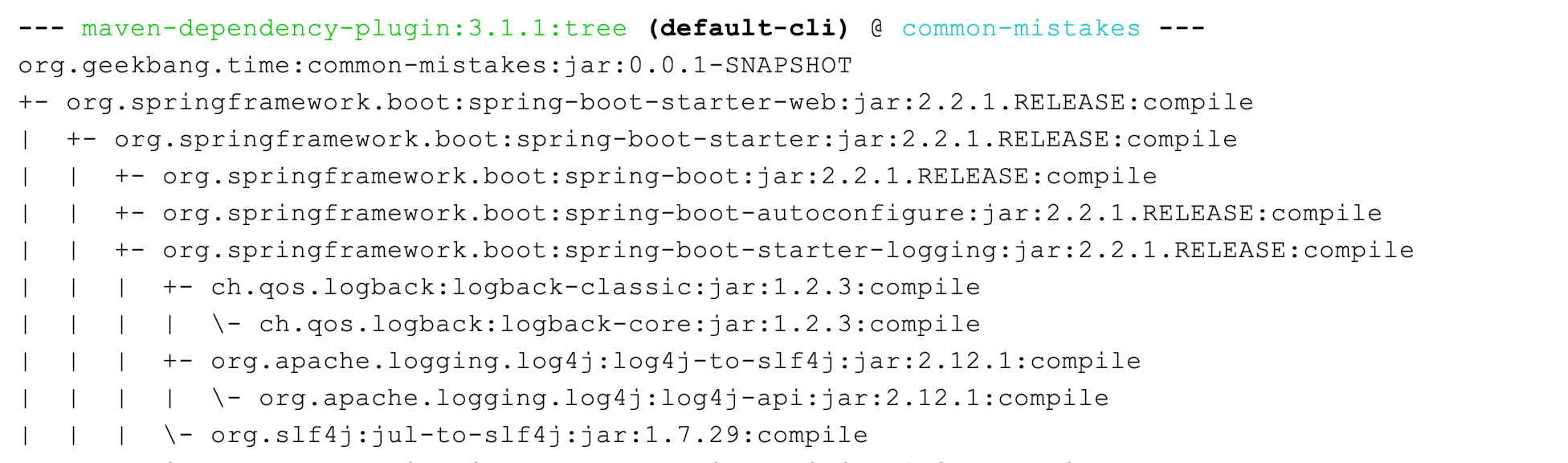
虽然图中有 4 个灰色的日志实现框架,但我看到的业务系统使用最广泛的是 Logback 和 Log4j,它们是同一人开发的。Logback 可以认为是 Log4j 的改进版本,我更推荐使用 , Spring Boot 是目前最流行的 Java 框架,它的日志框架也用的是 Logback 。
查看 Spring Boot 的 Maven 依赖树,可以发现 spring-boot-starter 模块依赖了 spring-boot-starter-logging 模块,而 spring-boot-starter-logging 模块又帮我们自动引入了 logback-classic(包含了 SLF4J 和 Logback 日志框架)和 SLF4J 的一些适配器。其中,log4j-to-slf4j 用于实现 Log4j2 API 到 SLF4J 的桥接,jul-to-slf4j 则是实现 java.util.logging API 到 SLF4J 的桥接 :
为什么我的日志会重复记录
日志重复记录在业务上非常常见,不但给查看日志和统计工作带来不必要的麻烦,还会增加磁盘和日志收集系统的负担
第一个案例是,logger 配置继承关系导致日志重复记录。
首先,定义一个方法实现 debug、info、warn 和 error 四种日志的记录:
1 | 4j2 |
使用下面的 Logback 配置:
- 第 11 和 12 行设置了全局的日志级别为 INFO,日志输出使用 CONSOLE Appender。
- 第 3 到 7 行,首先将 CONSOLE Appender 定义为 ConsoleAppender,也就是把日志输出到控制台(System.out/System.err);然后通过 PatternLayout 定义了日志的输出格式。关于格式化字符串的各种使用方式,你可以进一步查阅官方文档。
- 第 8 到 10 行实现了一个 Logger 配置,将应用包的日志级别设置为 DEBUG、日志输出同样使用 CONSOLE Appender。
1 |
|
这段配置看起来没啥问题,但执行方法后出现了日志重复记录的问题:

从配置文件的第 9 和 12 行可以看到,CONSOLE 这个 Appender 同时挂载到了两个 Logger 上,一个是我们定义的 ,一个是 ,由于我们定义的 继承自 ,所以同一条日志既会通过 logger 记录,也会发送到 root 记录,因此应用 package 下的日志出现了重复记录。
这个同学如此配置的初衷是实现自定义的 logger 配置,让应用内的日志暂时开启 DEBUG 级别的日志记录。其实,他完全不需要重复挂载 Appender,去掉 下挂载的 Appender 即可:
1 | <logger name="org.geekbang.time.commonmistakes.logging" level="DEBUG"/> |
如果自定义的 需要把日志输出到不同的 Appender,比如将应用的日志输出到文件 app.log、把其他框架的日志输出到控制台,可以设置 的 additivity 属性为 false,这样就不会继承 的 Appender 了:
1 |
|
第二个案例是,错误配置 LevelFilter 造成日志重复记录
一般互联网公司都会使用 ELK 三件套来统一收集日志,有一次我们发现 Kibana 上展示的日志有部分重复,一直怀疑是 Logstash 配置错误,但最后发现还是 Logback 的配置错误引起的。这个项目的日志是这样配置的:在记录日志到控制台的同时,把日志记录按照不同的级别记录到两个文件中:
1 |
|
第 31 到 35 行定义的 root 引用了三个 Appender。
第 5 到 9 行是第一个 ConsoleAppender,用于把所有日志输出到控制台。
第 10 到 19 行定义了一个 FileAppender,用于记录文件日志,并定义了文件名、记录日志的格式和编码等信息。最关键的是,第 12 到 14 行定义的 LevelFilter 过滤日志,将过滤级别设置为 INFO,目的是希望 _info.log 文件中可以记录 INFO 级别的日志。
第 20 到 30 行定义了一个类似的 FileAppender,并使用 ThresholdFilter 来过滤日志,过滤级别设置为 WARN,目的是把 WARN 以上级别的日志记录到另一个 _error.log 文件中。
运行一下测试程序:

可以看到,_info.log 中包含了 INFO、WARN 和 ERROR 三个级别的日志,不符合我们的预期;error.log 包含了 WARN 和 ERROR 两个级别的日志。因此,造成了日志的重复收集。
为了分析日志重复的原因,我们来复习一下 ThresholdFilter 和 LevelFilter 的配置方式。
分析 ThresholdFilter 的源码发现,当日志级别大于等于配置的级别时返回 NEUTRAL,继续调用过滤器链上的下一个过滤器;否则,返回 DENY 直接拒绝记录日志:
1 | public class ThresholdFilter extends Filter<ILoggingEvent> { |
在这个案例中,把 ThresholdFilter 设置为 WARN,可以记录 WARN 和 ERROR 级别的日志。
LevelFilter 用来比较日志级别,然后进行相应处理:如果匹配就调用 onMatch 定义的处理方式,默认是交给下一个过滤器处理(AbstractMatcherFilter 基类中定义的默认值);否则,调用 onMismatch 定义的处理方式,默认也是交给下一个过滤器处理。
1 | public class LevelFilter extends AbstractMatcherFilter<ILoggingEvent> { |
和 ThresholdFilter 不同的是,LevelFilter 仅仅配置 level 是无法真正起作用的。由于没有配置 onMatch 和 onMismatch 属性,所以相当于这个过滤器是无用的,导致 INFO 以上级别的日志都记录了。定位到问题后,修改方式就很明显了:配置 LevelFilter 的 onMatch 属性为 ACCEPT,表示接收 INFO 级别的日志;配置 onMismatch 属性为 DENY,表示除了 INFO 级别都不记录:
1 | <appender name="INFO_FILE" class="ch.qos.logback.core.FileAppender"> |
使用异步日志改善性能的坑
掌握了把日志输出到文件中的方法后,我们接下来面临的问题是,如何避免日志记录成为应用的性能瓶颈。这可以帮助我们解决,磁盘(比如机械磁盘)IO 性能较差、日志量又很大的情况下,如何记录日志的问题。
定义如下的日志配置,一共有两个 Appender:
- FILE 是一个 FileAppender,用于记录所有的日志;
- CONSOLE 是一个 ConsoleAppender,用于记录带有 time 标记的日志。
1 |
|
这段代码中有个 EvaluatorFilter(求值过滤器),用于判断日志是否符合某个条件。在后续的代码中,我们会把大量日志输出到文件中,日志文件会非常大,如果性能测试结果也混在其中的话,就很难找到那条日志。所以,这里我们使用 EvaluatorFilter 对日志按照标记进行过滤,并将过滤出的日志单独输出到控制台上。在这个案例中,我们给输出测试结果的那条日志上做了 time 标记。配合使用标记和 EvaluatorFilter,实现日志的按标签过滤,是一个不错的小技巧。
使用 Logback 提供的 AsyncAppender 即可实现异步的日志记录。AsyncAppende 类似装饰模式,也就是在不改变类原有基本功能的情况下为其增添新功能。这样,我们就可以把 AsyncAppender 附加在其他的 Appender 上,将其变为异步的。定义一个异步 Appender ASYNCFILE,包装之前的同步文件日志记录的 FileAppender,就可以实现异步记录日志到文件:
1 | <appender name="ASYNCFILE" class="ch.qos.logback.classic.AsyncAppender"> |
关于 AsyncAppender 异步日志的坑,这些坑可以归结为三类:
记录异步日志撑爆内存;记录异步日志出现日志丢失;记录异步日志出现阻塞。
AsyncAppender 提供了一些配置参数,没用对的情况下可能导致日志丢失。我们结合相关源码分析一下:includeCallerData 用于控制是否收集调用方数据,默认是 false,此时方法行号、方法名等信息将不能显示(源码第 2 行以及 7 到 11 行)。
queueSize 用于控制阻塞队列大小,使用的 ArrayBlockingQueue 阻塞队列(源码第 15 到 17 行),默认大小是 256,即内存中最多保存 256 条日志。
discardingThreshold是控制丢弃日志的阈值,主要是防止队列满后阻塞。默认情况下,队列剩余量低于队列长度的 20%,就会丢弃 TRACE、DEBUG 和 INFO 级别的日志。(参见源码第 3 到 6 行、18 到 19 行、26 到 27 行、33 到 34 行、40 到 42 行)
neverBlock 用于控制队列满的时候,加入的数据是否直接丢弃,不会阻塞等待,默认是 false(源码第 44 到 68 行)。这里需要注意一下 offer 方法和 put 方法的区别,当队列满的时候 offer 方法不阻塞,而 put 方法会阻塞;neverBlock 为 true 时,使用 offer 方法。
1 | public class AsyncAppender extends AsyncAppenderBase<ILoggingEvent> { |
看到默认队列大小为 256,达到 80% 容量后开始丢弃 <=INFO 级别的日志后,我们就可以理解日志中为什么会丢失日志了。
我们可以继续分析下异步记录日志出现坑的原因。
queueSize 设置得特别大,就可能会导致 OOM。
queueSize 设置得比较小(默认值就非常小),且 discardingThreshold 设置为大于 0 的值(或者为默认值),队列剩余容量少于 discardingThreshold 的配置就会丢弃 <=INFO 的日志。这里的坑点有两个。一是,因为 discardingThreshold 的存在,设置 queueSize 时容易踩坑。比如,本例中最大日志并发是 1000,即便设置 queueSize 为 1000 同样会导致日志丢失。二是,discardingThreshold 参数容易有歧义,它不是百分比,而是日志条数。对于总容量 10000 的队列,如果希望队列剩余容量少于 1000 条的时候丢弃,需要配置为 1000。
neverBlock 默认为 false,意味着总可能会出现阻塞。如果 discardingThreshold 为 0,那么队列满时再有日志写入就会阻塞;如果 discardingThreshold 不为 0,也只会丢弃 <=INFO 级别的日志,那么出现大量错误日志时,还是会阻塞程序。
可以看出 queueSize、discardingThreshold 和 neverBlock 这三个参数息息相关,务必按需进行设置和取舍,到底是性能为先,还是数据不丢为先:
- 如果考虑绝对性能为先,那就设置 neverBlock 为 true,永不阻塞。
- 如果考虑绝对不丢数据为先,那就设置 discardingThreshold 为 0,即使是 <=INFO 的级别日志也不会丢,但最好把 queueSize 设置大一点,毕竟默认的 queueSize 显然太小,太容易阻塞。
- 如果希望兼顾两者,可以丢弃不重要的日志,把 queueSize 设置大一点,再设置一个合理的 discardingThreshold。
以上就是日志配置最常见的两个误区了
文件IO:实现高效正确的文件读写并非易事
有一个项目需要读取三方的对账文件定时对账,原先一直是单机处理的,没什么问题。后来为了提升性能,使用双节点同时处理对账,每一个节点处理部分对账数据,但新增的节点在处理文件中中文的时候总是读取到乱码。程序代码都是一致的,为什么老节点就不会有问题呢?我们知道,这很可能是写代码时没有注意编码问题导致的
当时出现问题的文件读取代码是这样的:
1 | char[] chars = new char[10]; |
显然,这里并没有指定以什么字符集来读取文件中的字符。查看JDK 文档可以发现,FileReader 是以当前机器的默认字符集来读取文件的,如果希望指定字符集的话,需要直接使用 InputStreamReader 和 FileInputStream。到这里我们就明白了,FileReader 虽然方便但因为使用了默认字符集对环境产生了依赖,这就是为什么老的机器上程序可以正常运作,在新节点上读取中文时却产生了乱码。
思考与讨论
Files.lines 方法进行流式处理,需要使用 try-with-resources 进行资源释放。那么,使用 Files 类中其他返回 Stream 包装对象的方法进行流式处理,比如 newDirectoryStream 方法返回 DirectoryStream,list、walk 和 find 方法返回 Stream,也同样有资源释放问题吗?
Java 的 File 类和 Files 类提供的文件复制、重命名、删除等操作,是原子性的吗?
先说下FileChannel 的 transfreTo 方法,这个方法出现在眼前很多次,因为之前看Kafka为什么吞吐量达的原因的时候,提到了2点:批处理思想和零拷贝;
批处理思想:就是对于Kafka内部很多地方来说,不是消息来了就发送,而是有攒一波发送一次,这样对于吞吐量有极大的提升,对于需要实时处理的情况,Kafka就不是很适合的原因;
零拷贝:Kafka快的另外一个原因是零拷贝,避免了内存态到内核态以及网络的拷贝,直接读取文件,发送到网络出去,零拷贝的含义不是没有拷贝,而是没有用户态到核心态的拷贝。
而在提到零拷贝的实现时,Java中说的就是FileChannel 的 transfreTo 方法。然后回答下问题:
第一个问题:
Files的相关方法文档描述:
When not using the try-with-resources construct, then directory stream’s close method should be invoked after iteration is completed so as to free any resources held for the open directory.
所以是需要手动关闭的。第二个问题:
没有原子操作,因此是线程不安全的。个人理解,其实即使加上了原子操作,也是鸡肋,不实用的很,原因是:File 类和 Files的相关操作,其实都是调用操作系统的文件系统操作,这个文件除了JVM操作外,可能别的也在操作,因此还不如不保证,完全基于操作系统的文件系统去保证相关操作的正确性。
序列化:一来一回你还是原来的你吗
序列化和反序列化需要确保算法一致
业务代码中涉及序列化时,很重要的一点是要确保序列化和反序列化的算法一致性。有一次我要排查缓存命中率问题,需要运维同学帮忙拉取 Redis 中的 Key,结果他反馈 Redis 中存的都是乱码,怀疑 Redis 被攻击了。其实呢,这个问题就是序列化算法导致的
Spring 提供的 4 种 RedisSerializer(Redis 序列化器):
默认情况下,RedisTemplate 使用 JdkSerializationRedisSerializer,也就是 JDK 序列化,容易产生 Redis 中保存了乱码的错觉。
通常考虑到易读性,可以设置 Key 的序列化器为 StringRedisSerializer。但直接使用 RedisSerializer.string(),相当于使用了 UTF_8 编码的 StringRedisSerializer,需要注意字符集问题。如果希望 Value 也是使用 JSON 序列化的话,可以把 Value 序列化器设置为 Jackson2JsonRedisSerializer。默认情况下,不会把类型信息保存在 Value 中,即使我们定义 RedisTemplate 的 Value 泛型为实际类型,查询出的 Value 也只能是 LinkedHashMap 类型。
如果希望直接获取真实的数据类型,你可以启用 Jackson ObjectMapper 的 activateDefaultTyping 方法,把类型信息一起序列化保存在 Value 中。
如果希望 Value 以 JSON 保存并带上类型信息,更简单的方式是,直接使用 RedisSerializer.json() 快捷方法来获取序列化器。
枚举作为 API 接口参数或返回值的两个大坑
在前面的例子中,我演示了如何把枚举序列化为索引值。但对于枚举,我建议尽量在程序内部使用,而不是作为 API 接口的参数或返回值,原因是枚举涉及序列化和反序列化时会有两个大坑。
第一个坑是,客户端和服务端的枚举定义不一致时,会出异常。
第二个坑,也是更大的坑,枚举序列化反序列化实现自定义的字段非常麻烦,会涉及 Jackson 的 Bug。比如,下面这个接口,传入枚举 List,为 List 增加一个 CENCELED 枚举值然后返回:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
enum StatusEnumClient {
CREATED(1, "已创建"),
PAID(2, "已支付"),
DELIVERED(3, "已送到"),
FINISHED(4, "已完成");
private final int status;
private final String desc;
StatusEnumClient(Integer status, String desc) {
this.status = status;
this.desc = desc;
}
}
//服务端比客户端多一个枚举值
enum StatusEnumServer {
...
CANCELED(5, "已取消");
private final int status;
private final String desc;
StatusEnumServer(Integer status, String desc) {
this.status = status;
this.desc = desc;
}
}
("queryOrdersByStatusList")
public List<StatusEnumServer> queryOrdersByStatus(@RequestBody List<StatusEnumServer> enumServers) {
enumServers.add(StatusEnumServer.CANCELED);
return enumServers;
}如果我们希望根据枚举的 Desc 字段来序列化,传入“已送到”作为入参:
会得到异常,提示“已送到”不是正确的枚举值:
显然,这里反序列化使用的是枚举的 name,序列化也是一样:
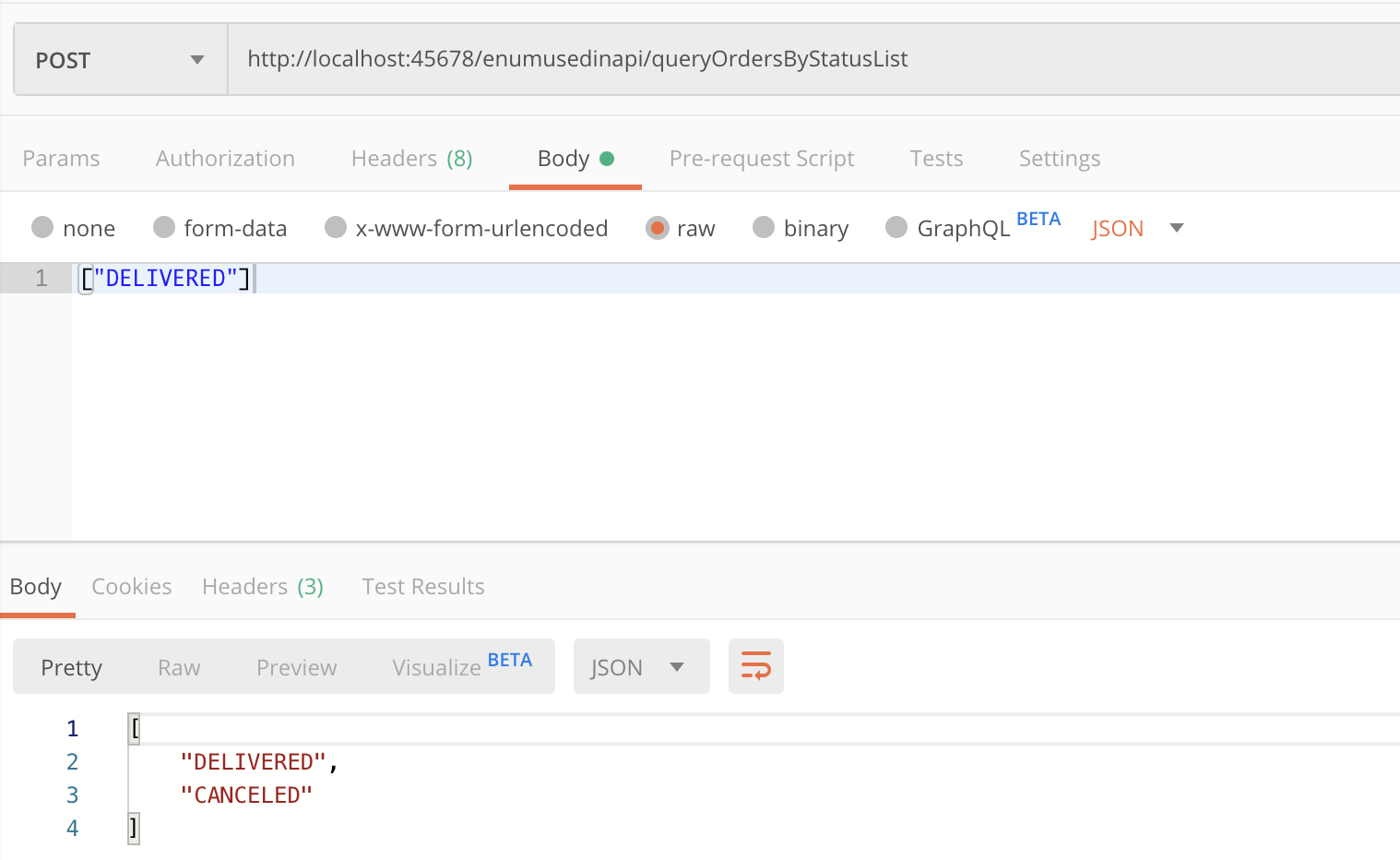
你可能也知道,要让枚举的序列化和反序列化走 desc 字段,可以在字段上加 @JsonValue 注解,修改 StatusEnumServer 和 StatusEnumClient:
1 |
|
然后再尝试下,果然可以用 desc 作为入参了,而且出参也使用了枚举的 desc:
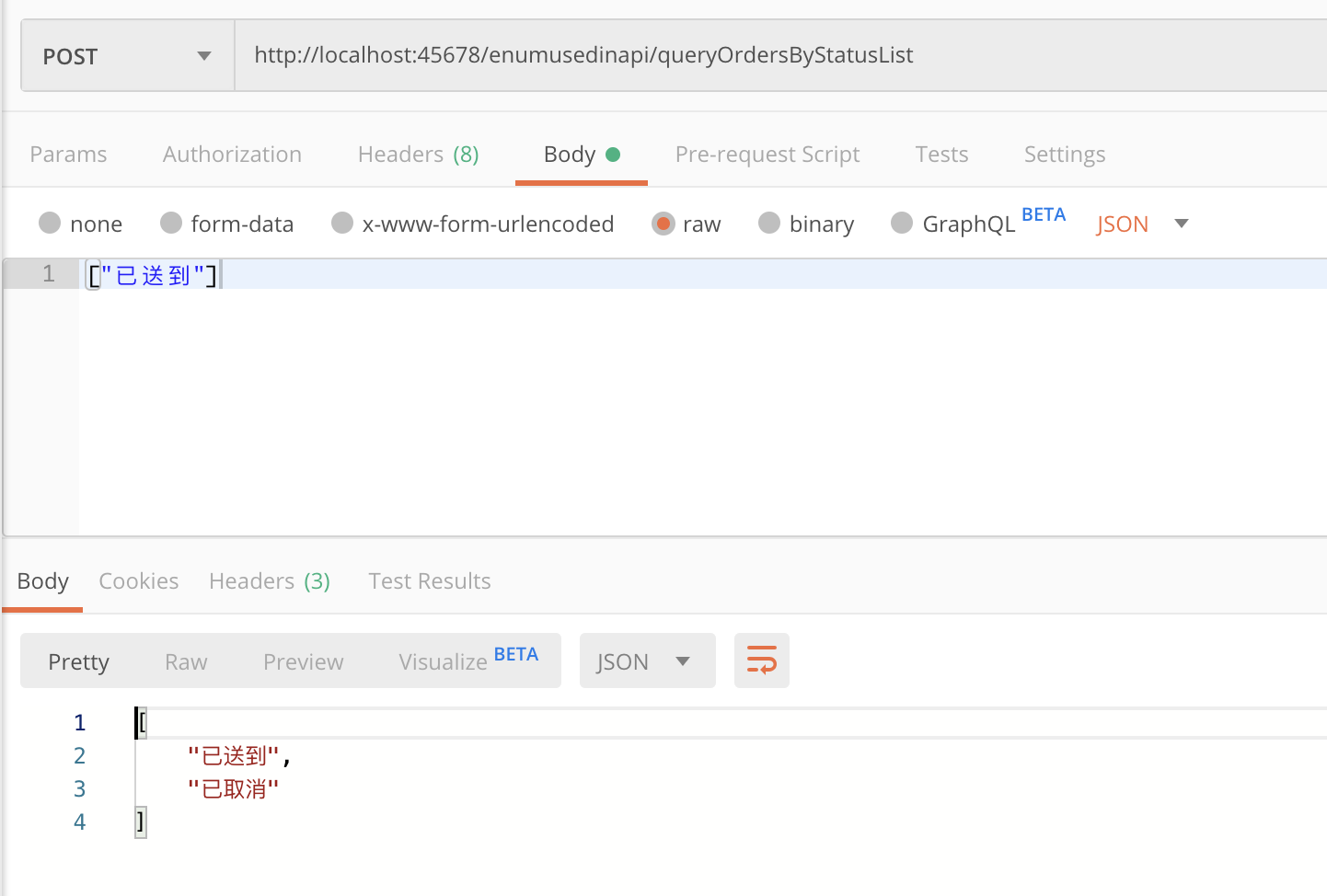
但是,如果你认为这样就完美解决问题了,那就大错特错了。你可以再尝试把 @JsonValue 注解加在 int 类型的 status 字段上,也就是希望序列化反序列化走 status 字段:
1 |
|
写一个客户端测试一下,传入 CREATED 和 PAID 两个枚举值:
1 | ("queryOrdersByStatusListClient") |
请求接口可以看到,传入的是 CREATED 和 PAID,返回的居然是 DELIVERED 和 FINISHED。果然如标题所说,一来一回你已不是原来的你
出现这个问题的原因是,序列化走了 status 的值,而反序列化并没有根据 status 来,还是使用了枚举的 ordinal() 索引值。这是 Jackson至今(2.10)没有解决的 Bug,应该会在 2.11 解决。
有一个解决办法是,设置 @JsonCreator 来强制反序列化时使用自定义的工厂方法,可以实现使用枚举的 status 字段来取值。我们把这段代码加在 StatusEnumServer 枚举类中:
1 |
|
要特别注意的是,我们同样要为 StatusEnumClient 也添加相应的方法。因为除了服务端接口接收 StatusEnumServer 参数涉及一次反序列化外,从服务端返回值转换为 List 还会有一次反序列化:
重新调用接口发现,虽然结果正确了,但是服务端不存在的枚举值 CANCELED 被设置为了 null,而不是 @JsonEnumDefaultValue 设置的 UNKNOWN。这个问题,我们之前已经通过设置 @JsonEnumDefaultValue 注解解决了,但现在又出现了:
1 | [22:20:13.727] [http-nio-45678-exec-1] [INFO ] [o.g.t.c.e.e.EnumUsedInAPIController:34 ] - result [CREATED, PAID, null] |
原因也很简单,我们自定义的 parse 方法实现的是找不到枚举值时返回 null。为彻底解决这个问题,并避免通过 @JsonCreator 在枚举中自定义一个非常复杂的工厂方法,我们可以实现一个自定义的反序列化器。这段代码比较复杂,我特意加了详细的注释:
1 | class EnumDeserializer extends JsonDeserializer<Enum> implements |
然后,把这个自定义反序列化器注册到 Jackson 中:
1 |
|
第二个大坑终于被完美地解决了:
1 | [22:32:28.327] [http-nio-45678-exec-1] [INFO ] [o.g.t.c.e.e.EnumUsedInAPIController:34 ] - result [CREATED, PAID, UNKNOWN] |
这样做,虽然解决了序列化反序列化使用枚举中自定义字段的问题,也解决了找不到枚举值时使用默认值的问题,但解决方案很复杂。因此,我还是建议在 DTO 中直接使用 int 或 String 等简单的数据类型,而不是使用枚举再配合各种复杂的序列化配置,来实现枚举到枚举中字段的映射,会更加清晰明了。
用好Java 8的日期时间类,少踩一些“老三样”的坑
在 Java 8 之前,我们处理日期时间需求时,使用 Date、Calender 和 SimpleDateFormat,来声明时间戳、使用日历处理日期和格式化解析日期时间。但是,这些类的 API 的缺点比较明显,比如可读性差、易用性差、使用起来冗余繁琐,还有线程安全问题。
关于 Date 类,我们要有两点认识:
一是,Date 并无时区问题,世界上任何一台计算机使用 new Date() 初始化得到的时间都一样。因为,Date 中保存的是 UTC 时间,UTC 是以原子钟为基础的统一时间,不以太阳参照计时,并无时区划分。
二是,Date 中保存的是一个时间戳,代表的是从 1970 年 1 月 1 日 0 点(Epoch 时间)到现在的毫秒数。尝试输出 Date(0):
对于国际化(世界各国的人都在使用)的项目,处理好时间和时区问题首先就是要正确保存日期时间。这里有两种保存方式:
方式一,以 UTC 保存,保存的时间没有时区属性,是不涉及时区时间差问题的世界统一时间。我们通常说的时间戳,或 Java 中的 Date 类就是用的这种方式,这也是推荐的方式。
方式二,以字面量保存,比如年 / 月 / 日 时: 分: 秒,一定要同时保存时区信息。只有有了时区信息,我们才能知道这个字面量时间真正的时间点,否则它只是一个给人看的时间表示,只在当前时区有意义。Calendar 是有时区概念的,所以我们通过不同的时区初始化 Calendar,得到了不同的时间。
要正确处理国际化时间问题,我推荐使用 Java 8 的日期时间类,即使用 ZonedDateTime 保存时间,然后使用设置了 ZoneId 的 DateTimeFormatter 配合 ZonedDateTime 进行时间格式化得到本地时间表示。这样的划分十分清晰、细化,也不容易出错。
使用遗留的 SimpleDateFormat,会遇到哪些问题:
日期时间格式化和解析
每到年底,就有很多开发同学踩时间格式化的坑,比如“这明明是一个 2019 年的日期,怎么使用 SimpleDateFormat 格式化后就提前跨年了” , 出现这个问题的原因在于,这位同学混淆了 SimpleDateFormat 的各种格式化模式。JDK 的文档中有说明:小写 y 是年,而大写 Y 是 week year,也就是所在的周属于哪一年。
除了格式化表达式容易踩坑外,SimpleDateFormat 还有两个著名的坑。
第一个坑是,定义的 static 的 SimpleDateFormat 可能会出现线程安全问题。
SimpleDateFormat 的作用是定义解析和格式化日期时间的模式。这,看起来这是一次性的工作,应该复用,但它的解析和格式化操作是非线程安全的。我们来分析一下相关源码:SimpleDateFormat 继承了 DateFormat,DateFormat 有一个字段 Calendar;SimpleDateFormat 的 parse 方法调用 CalendarBuilder 的 establish 方法,来构建 Calendar;establish 方法内部先清空 Calendar 再构建 Calendar,整个操作没有加锁。显然,如果多线程池调用 parse 方法,也就意味着多线程在并发操作一个 Calendar,可能会产生一个线程还没来得及处理 Calendar 就被另一个线程清空了的情况:
1 | public abstract class DateFormat extends Format { |
第二个坑是,当需要解析的字符串和格式不匹配的时候,SimpleDateFormat 表现得很宽容,还是能得到结果。比如,我们期望使用 yyyyMM 来解析 20160901 字符串:
1 | String dateString = "20160901"; |
居然输出了 2091 年 1 月 1 日,原因是把 0901 当成了月份,相当于 75 年:
1 | result:Mon Jan 01 00:00:00 CST 2091 |
对于 SimpleDateFormat 的这三个坑,我们使用 Java 8 中的 DateTimeFormatter 就可以避过去。首先,使用 DateTimeFormatterBuilder 来定义格式化字符串,不用去记忆使用大写的 Y 还是小写的 Y,大写的 M 还是小写的 m:
1 | private static DateTimeFormatter dateTimeFormatter = new DateTimeFormatterBuilder() |
其次,DateTimeFormatter 是线程安全的,可以定义为 static 使用;最后,DateTimeFormatter 的解析比较严格,需要解析的字符串和格式不匹配时,会直接报错,而不会把 0901 解析为月份。
对日期时间做计算操作,Java 8 日期时间 API 会比 Calendar 功能强大很多。
第一,可以使用各种 minus 和 plus 方法直接对日期进行加减操作,比如如下代码实现了减一天和加一天,以及减一个月和加一个月:
第二,还可以通过 with 方法进行快捷时间调节,比如:
使用 TemporalAdjusters.firstDayOfMonth 得到当前月的第一天;
使用 TemporalAdjusters.firstDayOfYear() 得到当前年的第一天;
使用 TemporalAdjusters.previous(DayOfWeek.SATURDAY) 得到上一个周六;
使用 TemporalAdjusters.lastInMonth(DayOfWeek.FRIDAY) 得到本月最后一个周五。
第三,可以直接使用 lambda 表达式进行自定义的时间调整。
使用 Java 8 操作和计算日期时间虽然方便,但计算两个日期差时可能会踩坑:Java 8 中有一个专门的类 Period 定义了日期间隔,通过 Period.between 得到了两个 LocalDate 的差,返回的是两个日期差几年零几月零几天。如果希望得知两个日期之间差几天,直接调用 Period 的 getDays() 方法得到的只是最后的“零几天”,而不是算总的间隔天数。
可以使用 ChronoUnit.DAYS.between 解决这个问题:
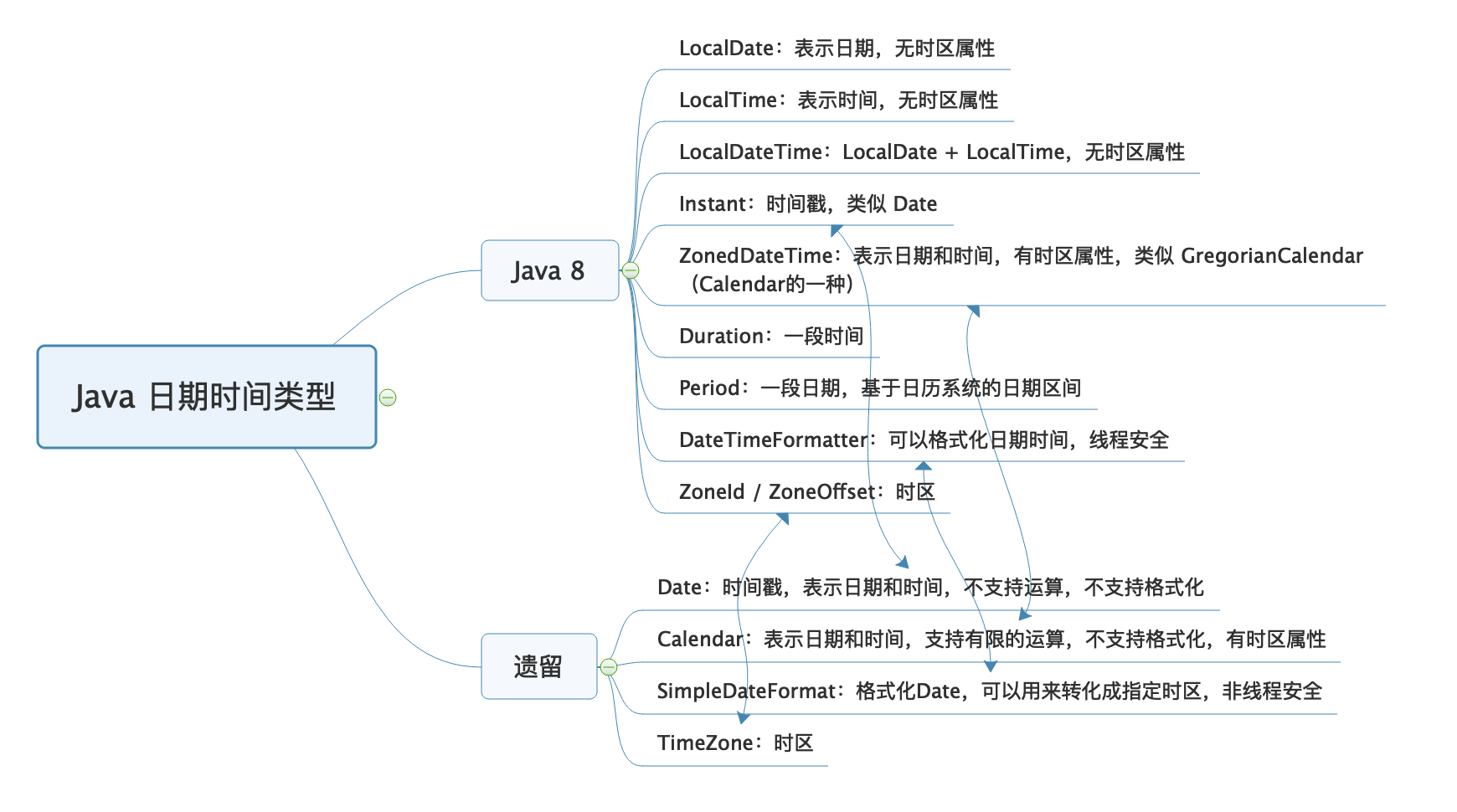
如果有条件的话,我还是建议全面改为使用 Java 8 的日期时间类型。我把 Java 8 前后的日期时间类型,汇总到了一张思维导图上,图中箭头代表的是新老类型在概念上等价的类型:
思考与讨论:
我今天多次强调 Date 是一个时间戳,是 UTC 时间、没有时区概念,为什么调用其 toString 方法会输出类似 CST 之类的时区字样呢?
日期时间数据始终要保存到数据库中,MySQL 中有两种数据类型 datetime 和 timestamp 可以用来保存日期时间。你能说说它们的区别吗,它们是否包含时区信息呢?
第一个:
Date的toString()方法处理的,同String中有BaseCalendar.Date date = normalize();
而normalize中进行这样处理cdate = (BaseCalendar.Date) cal.getCalendarDate(fastTime,TimeZone.getDefaultRef();
因此其实是获取当前的默认时区的。
第二个:
从下面几个维度进行区分:
占用空间:datetime:8字节。timestamp 4字节
表示范围:datetime ‘1000-01-01 00:00:00.000000’ to ‘9999-12-31 23:59:59.999999’
timestamp ‘1970-01-01 00:00:01.000000’ to ‘2038-01-19 03:14:07.999999’
时区:timestamp 只占 4 个字节,而且是以utc的格式储存, 它会自动检索当前时区并进行转换。
datetime以 8 个字节储存,不会进行时区的检索.
也就是说,对于timestamp来说,如果储存时的时区和检索时的时区不一样,那么拿出来的数据也不一样。对于datetime来说,存什么拿到的就是什么。
更新:timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP;
这个特性是自动初始化和自动更新(Automatic Initialization and Updating)。
自动更新指的是如果修改了其它字段,则该字段的值将自动更新为当前系统时间。
它与“explicit_defaults_for_timestamp”参数有关。By default, the first TIMESTAMP column has both DEFAULT CURRENT_TIMESTAMP and ON UPDATE CURRENT_TIMESTAMP if neither is specified explicitly。
很多时候,这并不是我们想要的,如何禁用呢?
\1. 将“explicit_defaults_for_timestamp”的值设置为ON。
\2. “explicit_defaults_for_timestamp”的值依旧是OFF,也有两种方法可以禁用
1> 用DEFAULT子句该该列指定一个默认值
2> 为该列指定NULL属性。在MySQL 5.6.5版本之前,Automatic Initialization and Updating只适用于TIMESTAMP,而且一张表中,最多允许一个TIMESTAMP字段采用该特性。从MySQL 5.6.5开始,Automatic Initialization and Updating同时适用于TIMESTAMP和DATETIME,且不限制数量。
OOM相关
Spring 提供的ConcurrentReferenceHashMap类可以使用弱引用、软引用做缓存,Key 和 Value 同时被软引用或弱引用包装,也能解决相互引用导致的数据不能释放问题。与 WeakHashMap 相比,ConcurrentReferenceHashMap 不但性能更好,还可以确保线程安全。你可以自己做实验测试下。
建议你为生产系统的程序配置 JVM 参数启用详细的 GC 日志,方便观察垃圾收集器的行为,并开启 HeapDumpOnOutOfMemoryError,以便在出现 OOM 时能自动 Dump 留下第一问题现场。对于 JDK8,你可以这么设置:
1 | XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=. -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:gc.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M |
反射相关
使用反射查询类方法清单时,我们要注意两点:getMethods 和 getDeclaredMethods 是有区别的,前者可以查询到父类方法,后者只能查询到当前类。反射进行方法调用要注意过滤桥接方法。
使用 Java 反射、注解和泛型高级特性配合 OOP 时,可能会遇到的一些坑。
- 第一,反射调用方法并不是通过调用时的传参确定方法重载,而是在获取方法的时候通过方法名和参数类型来确定的。遇到方法有包装类型和基本类型重载的时候,你需要特别注意这一点。
- 第二,反射获取类成员,需要注意 getXXX 和 getDeclaredXXX 方法的区别,其中 XXX 包括 Methods、Fields、Constructors、Annotations。这两类方法,针对不同的成员类型 XXX 和对象,在实现上都有一些细节差异,详情请查看官方文档。今天提到的 getDeclaredMethods 方法无法获得父类定义的方法,而 getMethods 方法可以,只是差异之一,不能适用于所有的 XXX。
- 第三,泛型因为类型擦除会导致泛型方法 T 占位符被替换为 Object,子类如果使用具体类型覆盖父类实现,编译器会生成桥接方法。这样既满足子类方法重写父类方法的定义,又满足子类实现的方法有具体的类型。使用反射来获取方法清单时,你需要特别注意这一点。
- 第四,自定义注解可以通过标记元注解 @Inherited 实现注解的继承,不过这只适用于类。如果要继承定义在接口或方法上的注解,可以使用 Spring 的工具类 AnnotatedElementUtils,并注意各种 getXXX 方法和 findXXX 方法的区别,详情查看Spring 的文档AnnotatedElementUtils。最后,我要说的是。编译后的代码和原始代码并不完全一致,编译器可能会做一些优化,加上还有诸如 AspectJ 等编译时增强框架,使用反射动态获取类型的元数据可能会和我们编写的源码有差异,这点需要特别注意。你可以在反射中多写断言,遇到非预期的情况直接抛异常,避免通过反射实现的业务逻辑不符合预期。
springaop
Bean 默认是单例的,所以单例的 Controller 注入的 Service 也是一次性创建的,即使 Service 本身标识了 prototype 的范围也没用。修复方式是,让 Service 以代理方式注入。这样虽然 Controller 本身是单例的,但每次都能从代理获取 Service。这样一来,prototype 范围的配置才能真正生效:
1 | (value = ConfigurableBeanFactory.SCOPE_PROTOTYPE, proxyMode = ScopedProxyMode.TARGET_CLASS) |
1 |
|
我们要知道切入的连接点是方法,注解定义在类上是无法直接从方法上获取到注解的。修复方式是,改为优先从方法获取,如果获取不到再从类获取,如果还是获取不到再使用默认的注解:
1 | Metrics metrics = signature.getMethod().getAnnotation(Metrics.class); |
接口统一包装
分享一个小技巧。为了简化服务端代码,我们可以把包装 API 响应体 APIResponse 的工作交由框架自动完成,这样直接返回 DTO OrderInfo 即可。对于业务逻辑错误,可以抛出一个自定义异常:
1 | ("server") |
在 APIException 中包含错误码和错误消息:
1 | public class APIException extends RuntimeException { |
然后,定义一个 @RestControllerAdvice 来完成自动包装响应体的工作:通过实现 ResponseBodyAdvice 接口的 beforeBodyWrite 方法,来处理成功请求的响应体转换。实现一个 @ExceptionHandler 来处理业务异常时,APIException 到 APIResponse 的转换。
1 | //此段代码只是Demo,生产级应用还需要扩展很多细节 |
缓存设计
注意缓存数据同步策略
在实际情况下,修改了原始数据后,考虑到缓存数据更新的及时性,我们可能会采用主动更新缓存的策略。这些策略可能是:
- 先更新缓存,再更新数据库;
- 先更新数据库,再更新缓存;
- 先删除缓存,再更新数据库,访问的时候按需加载数据到缓存;
- 先更新数据库,再删除缓存,访问的时候按需加载数据到缓存。
那么,我们应该选择哪种更新策略呢?逐一分析下这 4 种策略:
“先更新缓存再更新数据库”策略不可行。数据库设计复杂,压力集中,数据库因为超时等原因更新操作失败的可能性较大,此外还会涉及事务,很可能因为数据库更新失败,导致缓存和数据库的数据不一致。
“先更新数据库再更新缓存”策略不可行。一是,如果线程 A 和 B 先后完成数据库更新,但更新缓存时却是 B 和 A 的顺序,那很可能会把旧数据更新到缓存中引起数据不一致;二是,我们不确定缓存中的数据是否会被访问,不一定要把所有数据都更新到缓存中去。
“先删除缓存再更新数据库,访问的时候按需加载数据到缓存”策略也不可行。在并发的情况下,很可能删除缓存后还没来得及更新数据库,就有另一个线程先读取了旧值到缓存中,如果并发量很大的话这个概率也会很大。
“先更新数据库再删除缓存,访问的时候按需加载数据到缓存”策略是最好的。虽然在极端情况下,这种策略也可能出现数据不一致的问题,但概率非常低,基本可以忽略。举一个“极端情况”的例子,比如更新数据的时间节点恰好是缓存失效的瞬间,这时 A 先读取到了旧值,随后在 B 操作数据库完成更新并且删除了缓存之后,A 再把旧值加入缓存。
需要注意的是,更新数据库后删除缓存的操作可能失败,如果失败则考虑把任务加入延迟队列进行延迟重试,确保数据可以删除,缓存可以及时更新。因为删除操作是幂等的,所以即使重复删问题也不是太大,这又是删除比更新好的一个原因。因此,针对缓存更新更推荐的方式是,缓存中的数据不由数据更新操作主动触发,统一在需要使用的时候按需加载,数据更新后及时删除缓存中的数据即可。
JAVA8新特性
1 | //Predicate接口是输入一个参数,返回布尔值。我们通过and方法组合两个Predicate条件,判断是否值大于0并且是偶数 |
有很多类似使用 threadCount 个线程对某个方法总计执行 taskCount 次操作的案例,用于演示并发情况下的多线程问题或多线程处理性能。除了会用到并行流,我们有时也会使用线程池或直接使用线程进行类似操作。为了方便你对比各种实现,这里我一次性给出实现此类操作的五种方式。
为了测试这五种实现方式,我们设计一个场景:使用 20 个线程(threadCount)以并行方式总计执行 10000 次(taskCount)操作。因为单个任务单线程执行需要 10 毫秒(任务代码如下),也就是每秒吞吐量是 100 个操作,那 20 个线程 QPS 是 2000,执行完 10000 次操作最少耗时 5 秒。
1 | private void increment(AtomicInteger atomicInteger) { |
现在我们测试一下这五种方式,是否都可以利用更多的线程并行执行操作。
第一种方式是使用线程。直接把任务按照线程数均匀分割,分配到不同的线程执行,使用 CountDownLatch 来阻塞主线程,直到所有线程都完成操作。这种方式,需要我们自己分割任务:
1 | private int thread(int taskCount, int threadCount) throws InterruptedException { |
第二种方式是,使用 Executors.newFixedThreadPool 来获得固定线程数的线程池,使用 execute 提交所有任务到线程池执行,最后关闭线程池等待所有任务执行完成:
1 | private int threadpool(int taskCount, int threadCount) throws InterruptedException { |
第三种方式是,使用 ForkJoinPool 而不是普通线程池执行任务。
ForkJoinPool 和传统的 ThreadPoolExecutor 区别在于,前者对于 n 并行度有 n 个独立队列,后者是共享队列。如果有大量执行耗时比较短的任务,ThreadPoolExecutor 的单队列就可能会成为瓶颈。这时,使用 ForkJoinPool 性能会更好。
因此,ForkJoinPool 更适合大任务分割成许多小任务并行执行的场景,而 ThreadPoolExecutor 适合许多独立任务并发执行的场景。在这里,我们先自定义一个具有指定并行数的 ForkJoinPool,再通过这个 ForkJoinPool 并行执行操作:
1 | private int forkjoin(int taskCount, int threadCount) throws InterruptedException { |
第四种方式是,直接使用并行流,并行流使用公共的 ForkJoinPool,也就是 ForkJoinPool.commonPool()。公共的 ForkJoinPool 默认的并行度是 CPU 核心数 -1,原因是对于 CPU 绑定的任务分配超过 CPU 个数的线程没有意义。由于并行流还会使用主线程执行任务,也会占用一个 CPU 核心,所以公共 ForkJoinPool 的并行度即使 -1 也能用满所有 CPU 核心。
这里,我们通过配置强制指定(增大)了并行数,但因为使用的是公共 ForkJoinPool,所以可能会存在干扰,你可以回顾下第 3 讲有关线程池混用产生的问题:
1 | private int stream(int taskCount, int threadCount) { |
第五种方式是,使用 CompletableFuture 来实现。CompletableFuture.runAsync 方法可以指定一个线程池,一般会在使用 CompletableFuture 的时候用到:
1 | private int completableFuture(int taskCount, int threadCount) throws InterruptedException, ExecutionException { |

